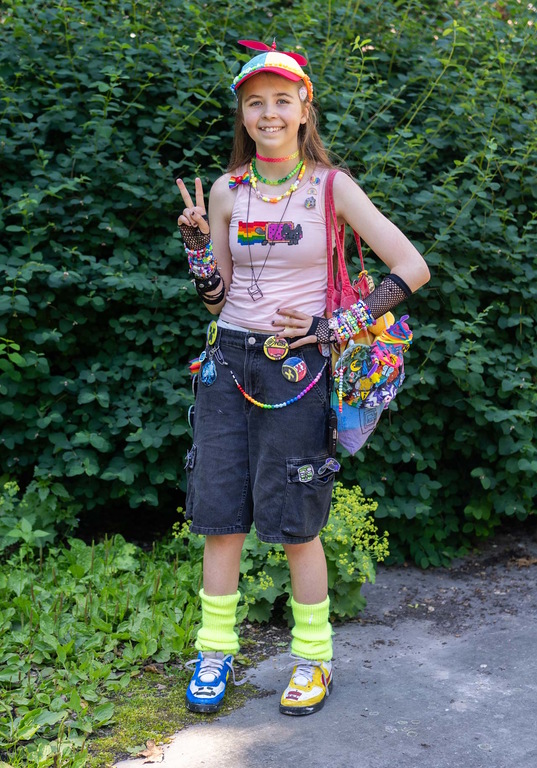Under ALAN, an extended photoperiod stimulates plant biomass, acting as a bottom-up C pump that enhances root exudation (rhizosphere priming effect) and accelerates C loss via respiration. Concurrently, ALAN is associated with a directional trend toward network structural fragmentation, potentially modifying trophic links between predators (nematodes) and prey.
ABSTRACT
Artificial light at night (ALAN) is an increasingly pervasive global change driver, yet its effects on the interconnected biogeochemical cycling of soil carbon (C) and nitrogen (N) remain poorly understood. Here, we conducted an in situ dual-isotope (13C-CO2 pulse labelling and 15N addition) experiment combined with multitrophic microbial network analysis in a semi-arid meadow steppe to explore the impact of ALAN on belowground C and N cycling and the underlying mechanisms. We found that ALAN significantly accelerated the turnover of newly fixed plant C, a process primarily fueled by the increased root-derived C input from ALAN-stimulated plant biomass (the bottom-up C-pump). Concurrently, while this plant-driven C surplus primarily fueled elevated soil respiration, ALAN substantially enhanced microbial 15N retention, resulting in a pronounced asymmetric biological allocation of assimilated C and N within the biotic pools. This stoichiometric divergence was underpinned by a physiological shift toward a conservative microbial N retention strategy, whereby soil microorganisms increased N retention efficiency to counterbalance the stoichiometric C surpluses induced by enhanced plant inputs. Crucially, we found that this enhanced biological N retention was predicted not by microbial taxonomic diversity but was closely associated with a directional trend toward reduced micro-food web structural connectivity. This fragmented network architecture potentially altered top-down trophic controls, which compounded the plant-driven stoichiometric imbalance by limiting predator-mediated N mineralization and thereby promoting relative N retention within the microbial biomass. Our findings highlight light pollution as an underappreciated global change driver that specifically accelerates plant-mediated bottom-up C loss while simultaneously promoting microbial N retention via fragmented micro-food webs in increasingly illuminated ecosystems.
Starting next week, Nebraskans on Medicaid will be at risk of losing their health coverage unless the state can verify that they work, volunteer, or attend school for 80 hours per month. Come January, millions of other low-income Americans will face the same cliff.
While some working-age people are exempt, including those with young children and those deemed “medically frail,” new rules about who can opt out have led to widespread confusion. For patients with complex medical conditions, the looming requirements may create another barrier to health.
“I’m wearing my jeans which I have sown old lace doilies and some self-made patches to, Tæl shirt which I bought from their gig and dyed with tea, a flannel shirt bought from Uff and my dad’s old hat. I’m the most inspired by the people I see, diy ethics, history and music like crust punk.”
“I’m wearing a pink tank top with a Nyan cat I painted. And I’m wearing jorts that my mum hated, but I love them. I’m an art student so I made almost all of the button pins and accessories myself, and also painted my shoes. My style is kidcore and I express my interests with color and art. I don’t like the idea that everyone should follow the same trends. I think diversity and variety are valuable.”
In light of yesterday’s attempt to publicly humiliate NIAID Director Anthony Fauci, this post I wrote a few days ago about a fundamental problem with COVID the lab leak hypothesis turned out to be timely. Anyway… When it comes to people who entertain the COVID lab leak hypothesis–or who support the notion wholeheartedly that the pandemic began with a leak from a research laboratory in Wuhan, China, there is always a piece of evidence that is never raised, even though it was discovered during the early stages of the pandemic. That is, there actually were two origins of COVID (boldface mine):
Furthermore, the COVID-19 pandemic was seeded more than once. Analyzing the virus sequences revealed that two genetically distinct versions of the virus were circulating. Tracing the virus’ evolution showed that SARS-CoV-2 spilled over to humans twice, a week or two apart. If this were a lab leak, one person would have needed to have been infected with lineage B in the lab and then traveled at least 30 minutes on a crowded subway without infecting anyone else until they got to the Huanan market and went to the southwest corner, where they shed virus all over stalls where multiple potential live intermediate hosts were being sold. The same thing would then need to happen two weeks later – completely independently – with lineage A.
The paper cited is from January 2022, so this is not some new data that people haven’t heard about yet. It was in the news at the time, though it was ignored as it was inconvenient for the lab leak proponents. While I don’t expect full-blown conspiracists to change their minds, I would expect that certain Very Serious People, such as certain NYT columnists or analysts at intelligence agencies, at least would offer an explanation for this, as two outbreaks from a laboratory that mimic the patterns we would expect to find with spread from wild animals sold at the Huanan market does strain credulity, if not annihilate it.
Cathy Barnhart is finally starting to enjoy her retirement, more than seven years after her career in health administration ended.
The North Bay, Ont. resident has been busy travelling to see her sons in Alberta and southern Ontario and planning a trip to Scotland with her husband.
At home, the 71-year-old has resumed long abandoned hobbies: researching her genealogy and playing the guitar.
A few years ago, all this seemed impossible. Climbing stairs exhausted Barnhart; she felt uneasy walking from her car into stores. Eventually, she stopped shopping almost altogether; what once had been enjoyable, now, inexplicably, was drudgery.
“I was just feeling unmotivated,” she said, reflecting on that time. “I was apathetic, like I wasn’t interested in anything.”
But Barnhart’s life began to change in January 2024 when she was diagnosed with idiopathic normal pressure hydrocephalus (iNPH).
Hydrocephalus occurs when excess fluid builds up in the brain, causing the ventricles to enlarge.
Anyone can be diagnosed with hydrocephalus at any time during their life. iNPH, however, is a distinct, age-related form typically diagnosed in adults over 60, with incidence rising sharply through the 70s and 80s.
Unlike secondary forms of normal pressure hydrocephalus, iNPH has no identifiable underlying cause. It is not the result of another condition, such as prior head injury or meningitis, that leads to fluid buildup in the brain.
iNPH is usually treated by surgically implanting a shunt in the brain that drains the excess fluid.
Barnhart had shunt surgery in December 2024. It has changed her life. Her energy has increased, and more importantly, her confidence.
She wonders how many people like her live with iNPH symptoms without realizing they have the condition — or that it can be treated.
“I just want them to know that it’s a possibility,” she said.
‘Very common’
Approximately one in 200 adults over 65 have normal pressure hydrocephalus, according to Hydrocephalus Canada. Often, the condition goes undiagnosed or misdiagnosed as a neurological disease, such as dementia.
“It is a very common condition, [it] is as common as Parkinson’s disease, and yet nobody talks about it,” said Dr. Alfonso Fasano, scientific director of the Surgical Program for Movement Disorders at Toronto Western Hospital.
“[Idiopathic normal pressure hydrocephalus] is becoming more and more common, because people live longer, and we know that age is the main risk factor.”
Yet despite this, many neurologists are not aware of the condition.
“[Idiopathic normal pressure hydrocephalus is] highly under-recognized, highly under-appreciated because there’s a lot of confusion when people talk about this group of patients,” said Dr. Mark Hamilton, director of the Adult Hydrocephalus Program at the University of Calgary.
People with untreated iNPH are more likely to die earlier. Treatments can dramatically improve patients’ lives, but must be done as soon as possible — if untreated, the condition can lead to irreversible brain damage.
iNPH has three main symptoms: incontinence or a sudden, strong urge to urinate; difficulty walking or with balance; and memory or cognitive challenges. Neurologists have to rule out many neurological diseases, such as Parkinson’s and Alzheimer’s as potential causes.
In iNPH patients, gait and bladder problems are present before memory difficulties, says Fasano. In dementia or Alzheimer’s, memory difficulties are not typically accompanied by gait problems.
An MRI is the best way to see if a patient has enlarged ventricles. But even then, other neurological conditions need to be ruled out, Fasano says.
‘Wet, wobbly, wonky’
Symptoms impact people differently.
Individuals with iNPH are often described as being “wet, wobbly and wonky,” said Barnhart. This was her experience for years.
It began in her final years of work with sudden, strong urges to urinate. At the time, she figured it was a regular part of aging. But then she started to feel more mentally overwhelmed at work.
“I just felt less able and more overwhelmed with work and family, not in a terrible way, but just enough that I felt something was different,” she said. She chalked it up to the stress of helping her recently widowed mother move to a retirement home.
“It’s not black-and-white,” she said of the difficulty of determining when her hydrocephalus symptoms began. “It’s [a] very slow and insidious type of progression.”
Difficulty walking was the final noticeable symptom. Barnhart had regularly exercised at a local gym for years, working with a personal trainer once a week. She could easily walk on a treadmill for nearly an hour and work out weights multiple times a week.
She shortened her personal training appointments and treadmill walks. When she was at the gym, she felt self-conscious, shy.
“I was kind of embarrassed about how I was functioning,” she said.
In his work with adult hydrocephalus patients, Dr. Hamilton regularly meets people who struggle with loneliness because of changes to their mobility.
“As your walking speed starts to fall and your balance fails, you become isolated,” said Hamilton.
People have a hard time leaving their homes and may struggle if their home has stairs.
A shunt can help people regain not only their mobility but also their confidence and social life.
A shunt is a device consisting of a thin tube and a valve that is surgically implanted to drain cerebrospinal fluid (CSF) buildup from the brain to another location in the body, usually the abdomen.
In his practice in Toronto, Fasano has seen patients regain their ability to walk after shunt surgery. Others have seen drastic improvements in their memory.
“There are some cases like this that you think the patient has no way to recover, and yet they recover,” he said. “That speaks to the resilience of the brain.”
Lifelong care
While a shunt can help improve function and restore independence, it is not a cure for the disease. Living with hydrocephalus can have some challenges, and organizations like Hydrocephalus Canada can provide information about the disease as well as personal support.
Patients who have shunts need to have their shunts monitored to make sure they continue to work properly.
“Hydrocephalus is a chronic disease and requires lifelong care. So putting a shunt in somebody doesn’t mean you’re cured, it’s just a way to control the disease,” said Hamilton, who has worked exclusively with adult hydrocephalus patients for 15 years.
Patients can benefit from physiotherapy and occupational therapy after a shunt surgery, he says. They may require care from a range of medical professionals.
Hamilton has led research showing patients benefit from their shunts long after the surgery.
But that is only possible if patients get a proper diagnosis at the right time.
“If you wait too long, the treatment is not going to benefit the patient as much as we want,” said Fasano.
Barnhart agrees. She says patients should talk to their doctor if they have symptoms and make sure they get an MRI to see if their ventricles are enlarged.
The benefits of the shunt are obvious to her. More than 18 months after her surgery, she still sees signs of improvement. Her energy levels are increasing, as is her walking speed and the amount of time she can exercise.
She intentionally works to better her memory by reading more books, completing Sudokus and learning the names of new people she meets.
She needs to: now that her iNPH is treated, she no longer keeps her head down while at the gym. Instead, she looks people in the eye again.
And sometimes, Barnhart forgets the diagnosis and surgery ever happened.
“I feel that probably, most people, once they have their shunt, they will get on with their life, and that’s what I’m trying to do now.”
Disclaimer: The opinions expressed are those of the participating healthcare provider(s) and patient and do not constitute medical advice. This content is for informational purposes only. Please consult your healthcare provider regarding any medical questions or treatment decisions. 7370763-1-EN